
✏️
Overview
We will discuss different types of data, how they are represented in R, and how data type influences the types of data analyses we may employ.
A practical benefit of understanding how R handles data is that a major source of error for novice R programmers is trying to use functions but providing the wrong type or class of data than what the function was written for. This is very confusing if you donʻt understand about objects in R, but very clear and easy to fix if you do!
Pre-lecture materials
Watch
Watch
Before class, you can prepare by watching:
Acknowledgements
Material for this lecture was borrowed and adopted from
- https://andreashandel.github.io/MADAcourse/Data_Types.html
- https://r-coder.com/data-types-r/#Raw_data_type_in_R
- https://www.stat.auckland.ac.nz/~paul/ItDT/HTML/node76.html # Learning objectives
Learning objectives
At the end of this lesson you will:
- Understand different types of data and how they are represented computationally
- Understand that different data types require different analysis approaches
- Recognize different base data types in R and know how to work with them
- Recognize the base data structures or objects in R and how to use them to do what you want
What is data anyway?
Merriam Webster defines data as factual information (such as measurements or statistics) used as a basis for reasoning, discussion, or calculation.
From a practicing scientistsʻ point of view, data is anything measureable or scorable that could provide information regarding a phenomenon of interest.
Ideally, data:
- are repeatable (at least within statistical error).
- contain more signal than noise.
For example, if we are studying how morphology changes with body size, we could take measurements such as body length, head length, arm length, and leg length on a sample of individuals. These measurements would provide linear, continuous data that would inform our study of size and scaling. If we also expected males and females to differ, then sex would be a categorical variable.
- It is important to define the variables so that the measurements are repeatable by other scientists collecting data on the same or similar samples.
- The variables chosen are expected to be related to the phenomenon of interest (here, scaling).
- The individuals are replicates from the same sample population, meaning that they should be equally embody or be influenced by the phenomenon we are studying. In other words, they form a homogenous sample. In the example of sexual dimorphism, we potentially have different groups within our sample. This can be taken account of in analyses using our categorical grouping variable sex.
Data have many forms such as images, sound, video, text, or any combination. Today we also have access to large volume datastreams from remote sensing, social media, or from all the various -omics. The kind of data, and how messy it is, determines the amount of processing that needs to be done before analysis.
At some point your data will most likely be arranged into spreadsheets, with observations as rows and variables as columns. In this course, we will focus on the data source that you are most likely to encounter in your analyses, the “(messy) spreadsheet” type, containing bits of information collected on individuals. Please do feel free to play around with other data types on your own, e.g. for your course project.
Types of Variables
Variables are the conceptual elements of the data. Variables are typically categorized by the nature of how they can vary (i.e., quantitative, qualitative, ordinal), because these differences dictate different analytical approaches and statistical methods.
Quantitative: This data type, also called metric data, represents variation in magnitude and generally allows one to do certain mathematical operations, e.g., subtraction or addition. The most common variations include:
- Continuous: Can take on any numerical value. Examples include mass, length, distance, age, etc.
- Discrete: Can only take countable (integer) values, e.g., the number of offspring an indivdiual produces.
- Fraction/Proportion: A continuous ratio of two values, with the numerator being a part to the whole which is represented by the demoninator. Thus these variables take on values between 0 and 1.
- Ratios: A continuous ratio of any two values. Data measured on a ratio scale have all the properties of continuous data.
Qualitative: Generally speaking, qualitative data indicate categories which have no intrinsic numeric value or natural order. Therefore it would not make sense to apply arithmetic to qualitative data such as color, sex, or family group, etc. You may see the term nominal (definition: “pertaining to names”) data applied to categorial data in the statistical literature. Major types of qualitative data include:
- Categorical: e.g., flower color, continent of origin, social status, disease state, etc.
- Descriptive: e.g., free text data from field observations.
Ordinal: Related to categorical data, this type differs in that they can be ranked, at least qualitatively.
For example, while body condition may be a qualitative assessment, “obese” clearly indicates greater fat stores than “well-conditioned”, which is greater than “emaciated”. Thus, ordinal data fall between being strictly quantitative or strictly qualitative. In some cases, if there are numerous categories, you can begin to think of them as approaching continuous data, although one important difference is that there is no clear numerical value that you can assign to the different categories (i.e., it is unclear whether the difference between obese and well-conditioned is the same as the difference between well-conditioned and emaciated). It may make sense to apply rank order statistics to ordinal data, but it would not make sense to add, subtract, or multiply these categories.
Analysis approaches and their relationship to data
It may be obvious that data type will dictate the types of analyses one can do. It might be less obvious that the question of interest and whether there is a quantitative or ordinal outcome also drive our analyitical approach.
When we want to know the strength of the quantitative relationship
Methods for quantitative responses (or outcomes) that address questions such as “how much does leg length increase with body size?”? In other words, “how much does variable Y change with each increment of change in variable X?” These are usually referred to as regression approaches.
There are many subtypes of regression such as linear regression for continuous outcomes, and Poisson regression for discrete outcomes.
- Linear regression predicts a continuous response, such as body size.
- Poisson regression predicts a count or discrete response, such as population size.
Both types of regression can be based independent variables that are continuous, discrete, or categorical (or some combination). They differ in the underlying distribution of the modeled response variable, often a normal distribution for linear regression, and a Poisson distribution for the Poisson regression.
When we want to know about grouping
Methods that recover categorical responses, in other words, categorizing observations based on the analysis of data, are usually referred to as classification approaches. These methods are useful for looking for order in nature, such as whether different species can be grouped into “ecomorphs” based on their morphology, or to predict the type of behavioral response (e.g., “attack” or “flee”) based on responses to different stimuli.
It is possible to obtain an ordinal response as well, using ordinal regression. Alternatively, the the response can be treated as unordered categorical or as continuous (depending on how you code them, i.e., in R as a factor or numeric).
There are no hard and fast rules regarding when it is appropriate to treat an ordinal variable as fully quantitative. It should, however, at least be explained or justified. You can always treat it as categorical, but then you lose some information on the ranking of the variable.
To add to the confusion, these classification methods are often based on regression, with the decision to classify based on one category or another dependent on comparing distances or probabilities based on regression results.1
Recently, there has been a lot of interest in AI and machine learning. This is often just a fancy way of renaming discriminant function analysis and cluster analysis. When you see supervised learning in the literature, it refers to cases when we have the categories predefined, and often we have a training dataset with data on individuals of each category to use to train the classification algorithm before we use it to predict grouping (i.e., discriminant function analysis). When we donʻt have the categories a priori, and the algorithms determine the categories and their number, these analysis methods are usually referred to as clustering approaches and are also called unsupervised learning methods.
We will return to and apply some of those methods later in the course.
Data types in R
Now that we have a basic understanding of the conceptual landscape of data, letʻs breifly discuss how these different types of data are represented in and handled by R.
If you would like a gentle video walk through/demonstration of data types, now would be a good time to check out the Types section of the RStudio programming basic primer. For more details and examples see chapter 3 of IDS.
Basic data types
R has six basic (atomic) types of data:
| Atomic Type | Short Description | Size in bytes |
|---|---|---|
| string (or character) | text | 1 (per character) |
| integer | countable numbers | 4 |
| real | real numbers | 8 |
| logical | TRUE or FALSE | 4 |
| complex | numbers with imaginary component | |
| raw | raw bytes | 1 |
All other data types are derived from the atomic types
Note: Most computers use 64-bit operating systems these days, so the sizes above are for 64-bit software.
For a quick tour of the data types, see https://r-coder.com/data-types-r
String/character: Character values are alphanumeric values (plus whitespace, punctuation, etc.). A string is a collection of characters, in other words “text”.
- strings can be pasted together using the
paste()function. - R has powerful tools for string manipulation, including searching, replacing, and customized partial matching (with or without replacement) using wildcards and perl-like regular expressions (or regex) using base functions such as
- There are also packages specific for string manipulation including the
stringrpackage which is part of the tidyverse.
It is very likely that you will need to work with strings at some point during a data analysis, even if it is only to find specific values, clean up variable names, etc.
These problems can be quite the headache! But instead of editing them by hand and possibly making an error, it is better to do this with code. It also makes it easier to keep a record of the original data and all of the changes made to it, improving the reproducibility of your analysis.
There is a learning curve to using these tools, especially regex syntax, but they are very powerful and well worth your time.
Good sources for practice manipulating strings:
- For beginners: Review the Strings chapter (14) of R4DS, and do the exercises.
- The string processing chapter (25) of IDS
- the Character Vectors chapter in the STAT 545 book by Jenny Bryan
Decide which one is right for your level and work through some examples. I think youʻll agree that it is worth your time.
Numeric (double or integer): Variables of type numeric in R are either integers or double precision (representing real numbers).
- Integers and real values are different, but in practice most R users donʻt pay attention to this distinction. Integer values tend to be coerced (converted) to real values if any mathematical operations are done to them.
- If an integer is explicity needed, you can create them using functions such as
as.integer(). - Note that when you type an integer value, e.g.
x <- 2, into R, this is considered numeric by default. - If you want to make sure a value is treated as integer, add an
L, e.g.x <- 2L.
Logical: Logical variables are binary and can take on only two values, TRUE or FALSE (which are reserved words that only take on these meanings in R).
- In R, logical values are treated as integers, and interpreted as 1 for
TRUEand 0 forFALSE. It is possible tosum(TRUE)or a vector of logicals, for example.
- R also understands
T,True, andtrueforTRUE, and the corresponding representations forFALSE. - Importantly, logical comparisons are used for indexing. You will use logical comparisons when cleaning and checking your data, or running analyses, e.g., if you want to see if your variable
xis greater than 5, then the R commandx > 5will return either TRUE or FALSE, based on the value ofx. - Note: reserved words are understood as constants and should not be “quoted”.
Derived data types
R also allows derived data types called classes that are built up from atomic data types. There are R base classes as well as new classes that can be defined as needed by programmers (maybe you?).
Factors: Are Rʻs class for categorical variables.
- Factors have names and values.
- For example, a size factor may have
names(orlevels) ofsmall,medium. andlargewith values 0,1,2. Here, the values simply indicate the different categories, with the names being the human-friendly labels for the values.
- Factors can be ordered/ordinal or not.
- Factors could be numeric values, e.g., the number of offspring.
- Or it could be a factor coding for 3 types of habitat (unordered),
- Or 3 levels of life history stage (ordered).
- An excellent package to work with factors is the
forcatspackage.
For more about factors, work through the Factors chapter of R4DS, and do the exercises.
Date/time: Dates in base R are of the class Date (and are called POSIX variables). The lubridate package is a tidyverse package to work with dates, which many people find easier. There are other packages as well.
Additional resources are the Dates and times chapter of R4DS and the Parsing Dates and Times chapter of IDS.
Programmer-defined classes Many packages define their own classes. For example class phylo is used to represent phylogenetic trees in the ape package.
There are several functions that can show you the data type of an R object
such as typeof(), mode(), storage.mode(), class() and str().
Data structures in R
Data in R are stored in data structures called objects.
Vectors: vectors are the simplest object, a collection of data elements in a single sequence.
- One way to create vectors is with the
concatenatecommand,c().
-
1:3is shorthand for a numeric sequence=c(1,2,3)
- A single vector can contain only one type (e.g., all characters or all numeric).
- If you try to mix and match, everything will default to the lowest common denominator, typically a character (anything can be a character).
What happened?
Matrices: A matrix is a rectangular collection of data elements in rows and columns.
- A matrix can contain only one type.
- Internally, R stores matrices as a long vector, keeping track of where the columm breaks are.
- Matrices are really important for the matrix math used to solve many statistical models.
Data frames: A data frame is a rectangular data structure that is designed to store records of individual subjects.
- A data frame has rows and columns.
- Columns are allowed to be of different data types (for example, “character” for the subject names and “numeric” for measured variables for each subject, and “factors” for categories such as sex, etc.).
- Internally, data frames are stored as a list of vectors, one for each column. This allows each column to have a different type.
- Each columm must have the same number of elements or rows, i.e., it must be rectangular.
- Typically, the columms of data frames have names corresponding to variable names.
Lists: Lists do not have to be rectangular and are the most flexible data type in R. A list is a vector possibly composed of different structures and of varying length (this is the only type where that is allowed!). > - Lists are commonly used for model fits in statistical functions. For example, you may want to store the model (an expression), the input data (a dataframe), the output coefficients (a vector), - R has many powerful functions that operate on lists.
Other types of data structures exist; they are often introduced by specific R packages. An important one to know is the tibble which is a type of data frame used in the tidyverse. It is similar, but not exactly like a data frame. You can read more about tibbles on its package website and in R4DS chapter 10.
Other derived data types
Timeseries: A very useful set of tools for times-series analysis in R is the set of packages called the tidyverts. CRAN also has a Task View for Time Series Analysis. (A Task View on CRAN is a site that tries to combine and summarize various R packages for a specific topic). Another task view that deals with longitudinal/time-series data is the Survival Analysis Task View.
Omics: The bioconductor website is your source for (almost) all tools and resources related to omics-type data analyses in R.
Text: Working with and analyzing larger sections of text is different from the simple string manipulation discussed above. These days, analysis of text often goes by the term natural language processing. Such text analysis will continue to increase in importance, given the increasing data streams of that type. If you are interested in doing full analyses of text data, the tidytext R package and the Text mining with R book are great resources. A short introduction to this topic is The text mining chapter (27) of IDS.
Images: Images are generally converted into multiple matrices of values for different pixels of an image. For instance, one could divide an image into a 100x100 grid of pixels, and assign each pixel a RGB values and intensity. That means one would have 4 matrices of numeric values, each of size 100x100. One would then perform operations on those values. We won’t do anything with images here, there are some R packages for analyzing image data.
Videos: Are a time-series of images. Analysis of videos therefore has an extra layer of complexity.
Attributes of Objects
Each object in R has certain characteristics called attributes. You can think of this as the metadata for R objects. These attributes are what allow functions written by anyone to be reusable by others, so long as the object is of the correct class.
The common attributes of objects (the most helpful to know are class, mode, length, dimension, and names:
-
classDescribes the derived type of object, it may be a built-in class or written by a package author or user. Classes are used for methods dispatch. -
modeOften describes the atomic type of object. Sometimes called storage mode. Can be the same as the class, if it is an atomic type. -
lengthThe number of fundamental elements of a vector. -
dimensionRectangular objects such as matrices and data frames have two dimensions, for the numbers of rows and columns (or the length of the vectors and numbers of vectors). 3D and higher dimensional arrays have 3 or more dimensions. -
namesNames are optional but often useful to apply labels to internal elements of objects. If no names are given, the internal values can be referenced by their position (index).
Helpful functions for creating objects
| Functions | Actions |
|---|---|
| c(n1, n2, n3) | combines elements into an object |
| cbind(x, y) | binds objects together by column |
| rbind(x, y) | binds objects together by row |
For sequences
| Functions | Actions |
|---|---|
| seq() | generate a sequence of numbers |
| 1:10 | sequence from 1 to 10 by 1 |
| rep(x, times) | replicates x |
| sample(x, size, replace=FALSE) | sample size elements from x |
| rnorm(n, mean=0, sd=1) | draw n samples from normal distribution |
Creating or Coercing objects to different class
| Functions | Actions |
|---|---|
| vector() | create a vector |
| matrix() | create a matrix |
| data.frame() | create a data frame |
| as.vector(x) | coerces x to vector |
| as.matrix(x) | coerces to matrix |
| as.data.frame(x) | coerces to data frame |
| as.character(x) | coerces to character |
| as.numeric(x) | coerces to numeric |
| factor(x) | creates factor levels for elements of x |
| levels() | orders the factor levels as specified |
Examples
Various ways to create vectors:
x <- c( 1, 5, 7, 2, 6) # numeric
x[1] 1 5 7 2 6rep( x, times=2) [1] 1 5 7 2 6 1 5 7 2 6y <- rnorm(8)
y[1] -1.5586869 0.8054835 -1.4944195 -0.3371260 2.2334499 -0.2534822 -1.4554866
[8] 0.3046668goodanswer <- c(TRUE, TRUE, FALSE) # logical
goodanswer[1] TRUE TRUE FALSEspecies <- letters[1:4] # special stored data object: lower case letters a - d
species[1] "a" "b" "c" "d"LETTERS[1:3] # A B C # character[1] "A" "B" "C"treatment <- c("low", "low", "high", "med", "high") # character vector
treatment[1] "low" "low" "high" "med" "high"treat <- factor(treatment) # create a factor
treat[1] low low high med high
Levels: high low medThe vector treat has five elements, it is factor with levels of low, med, or high.
It is simple to do arithmetic on numeric vectors:
x[1] 1 5 7 2 6x+2[1] 3 7 9 4 8x^2[1] 1 25 49 4 36Typically the class of a vector is returned as the type of information contained, so that return values of the atomic types “numeric”, “character”, “factor”, or “logical” indicate that the object is a vector:
Factors are categorical data
For example, large and small, or blue, red, and yellow. Factors may be ordered, which means that the order of the categories has meaning (like income categories). By default, factors are unordered. Levels are the categories that the factor can take on.
You can easily coerce one type to another:
as.numeric(treat) # coerce to numeric[1] 2 2 1 3 1as.character(y) # coerce to character[1] "-1.55868693158335" "0.805483463516522" "-1.49441946742258"
[4] "-0.337125974660089" "2.23344985377915" "-0.253482201387456"
[7] "-1.45548662051813" "0.304666751603889" Note that when values are quoted, they are of type character.
class("pony")[1] "character"However, notice that factors return different values for class and mode:
And sometimes, when doing ordinary manipulations such as coercing to numeric or combining vectors together to create a matrix, we get:
as.numeric(treat)[1] 2 2 1 3 1cbind(x, treat) x treat
[1,] 1 2
[2,] 5 2
[3,] 7 1
[4,] 2 3
[5,] 6 1plot(treat, x)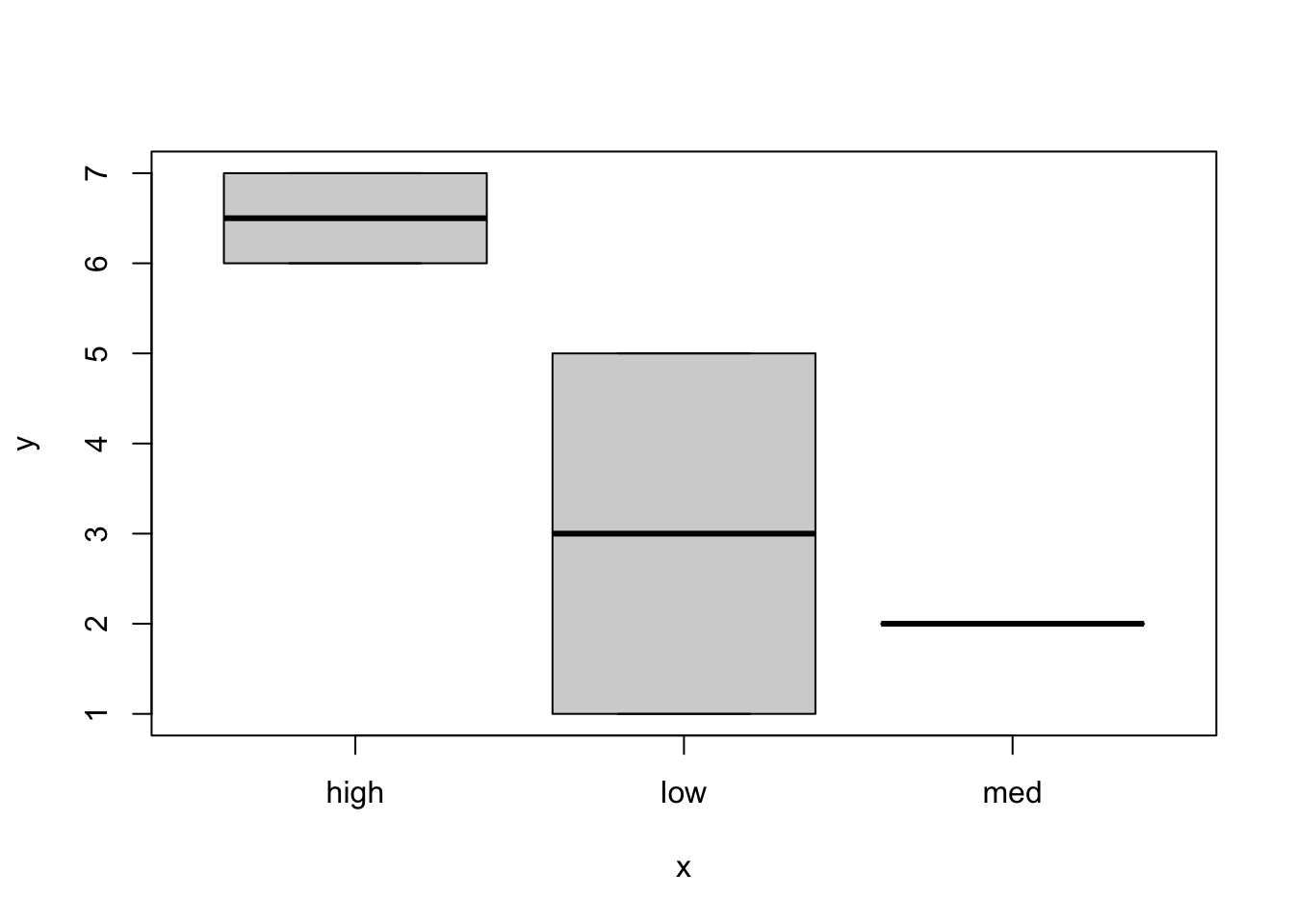
This is because internally, factors are stored as digits, 1, 2, etc. to the number of categories. The characters that you see are actually labels for the factor categories called “levels”. Look at the help page for factor (?factor) and read the entry for levels. If nothing is specified for the order of the levels, then they are numbered alphabetically! This explains the weird behavior. So if you want the order of the levels to be a more logical “low, medium, high”, you can do so by specifying the order of the levels explicitly when you create the factor:
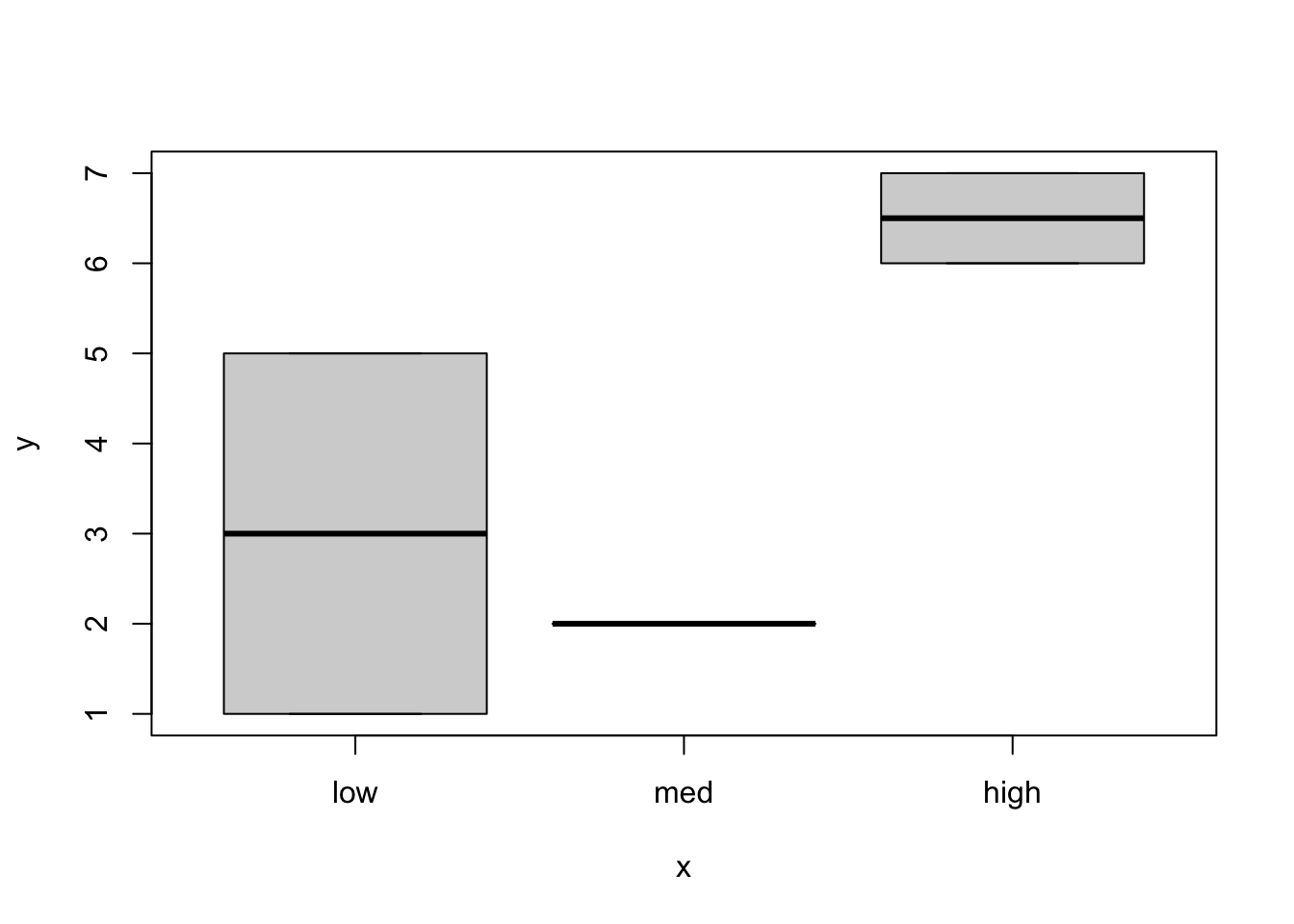
If you get frustrated because youʻre trying to treat a factor as a character, itʻs sometimes safer to manipulate factors by coercing to character first before doing anything else.
Hereʻs another illustration of methods dispatch - The plot function by default accepts arguments in x, y order. If x is a factor as above, the plot assumes a categorial format for the x-axis. However, if you switch the order:
plot(x,treat)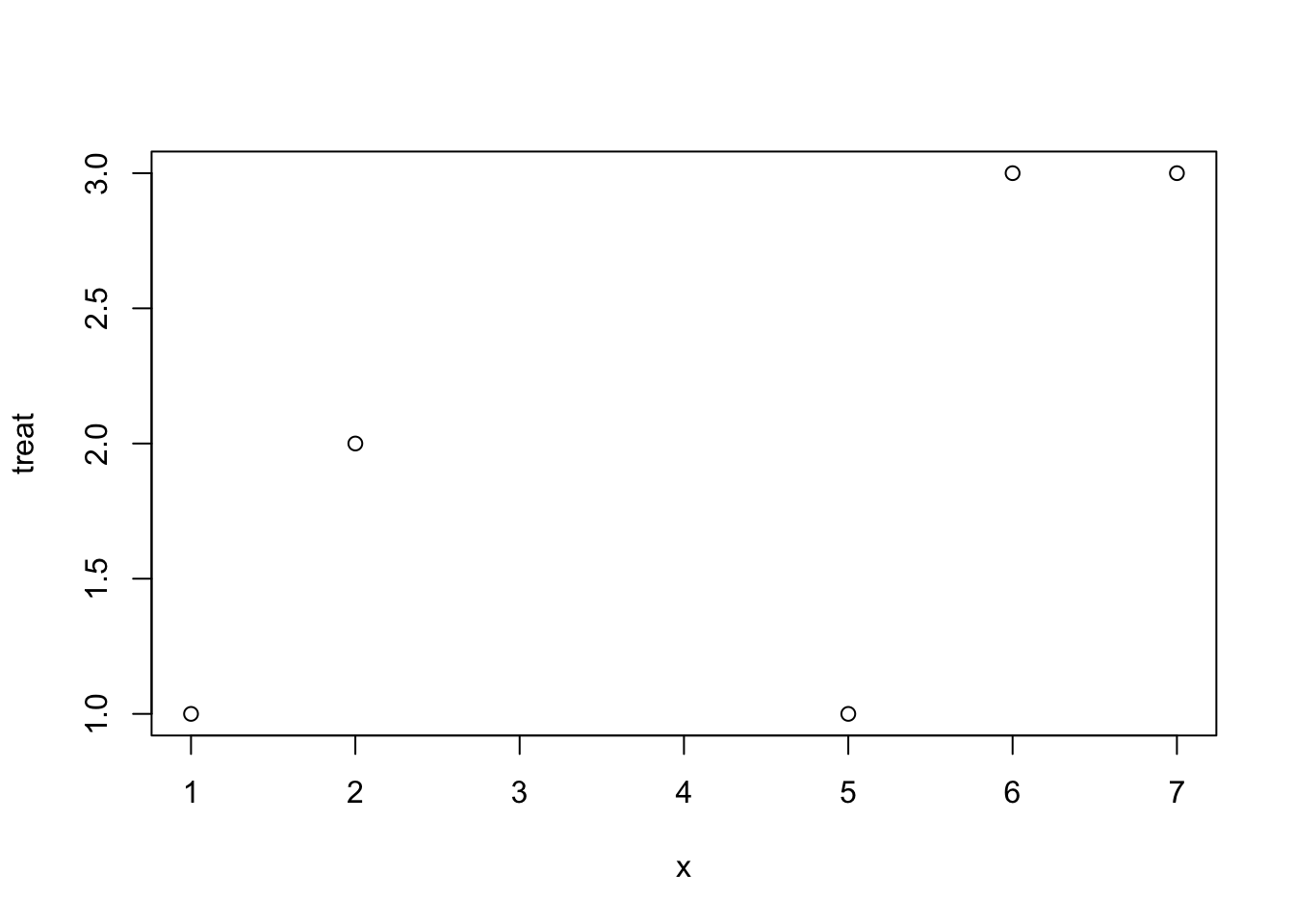
It is treated as a continuous x-axis. This is because methods dispatch for the plot function will be guided by the class of the objects that you supply. With x as a factor, R assumes you want a discrete x-axis, with the x as a continuous variable and y as the factor level, it will plot on the internal codes for the factor levels (if you want a horizontal bar plot use barplot(..., horiz=TRUE). If you want histograms use hist().
If you name a vector, the names are attached to each value:
Matrices
Data are often rectangular. For example, you might have height and weight columns for each subject (rows), or you might have a matrix describing the genetic relatedness between each pair of individuals in a family. Whether it is a square or a rectangular matrix, you will have a series of vectors of equal length. In fact, in R you can think of it as a single long vector with breaks at the end of each column.
Creating a matrix:
xy <- cbind(x,y) # column bindWarning in cbind(x, y): number of rows of result is not a multiple of vector
length (arg 1)xy x y
[1,] 1 -1.5586869
[2,] 5 0.8054835
[3,] 7 -1.4944195
[4,] 2 -0.3371260
[5,] 6 2.2334499
[6,] 1 -0.2534822
[7,] 5 -1.4554866
[8,] 7 0.3046668z <- matrix(1:6, nrow=2) #create a matrix with 2 rows
z [,1] [,2] [,3]
[1,] 1 3 5
[2,] 2 4 6matrix(1:6, nrow=2, byrow=2) [,1] [,2] [,3]
[1,] 1 2 3
[2,] 4 5 6class(z)[1] "matrix" "array" mode(z)[1] "numeric"Names applied to a matrix will attach the names to each value. If you want to name the rows and columns of a matrix you must use rownames() or colnames()
names(z) <- letters[1:6]
z [,1] [,2] [,3]
[1,] 1 3 5
[2,] 2 4 6
attr(,"names")
[1] "a" "b" "c" "d" "e" "f"z["c"]c
3 z["f"]f
6 tom dick harry
[1,] 1 3 5
[2,] 2 4 6
attr(,"names")
[1] "a" "b" "c" "d" "e" "f"Matrices have rows and columns, and are all of the same type whether it is numeric or character. There is a full suite of matrix math facilities in R to operate on numeric matrices.
Data Frames
Dataframes are superficially similar to matrices. They are rectangular. However, a major difference is that the vectors that comprise a dataframe can have vectors of different type. For example, one column can contain species names, whereas the other columns might contain numerical data.
species = letters[1:3]
y = rnorm(3)
dat <- data.frame(species, x, y)Internally, it is no longer a single vector but actually a list of vectors:
class(dat)[1] "data.frame"mode(dat)[1] "list"names(dat)[1] "species" "x" "y" length(dat)[1] 3dim(dat)[1] 3 3This is why the length of a dataframe is the number of columns. The names are the names of the columns, etc.
You can access the columns of dataframes using the $ operator, or using brackets, or by index number: and the name of the element, by the index number and double brackets, or by name and double bracket. Or a single value by using indexing on the row and column number separated by a comma. More on this later in the indexing chapter.
dat$species[1] "a" "b" "c"dat[1] species
1 a
2 b
3 cdat[1,3][1] 1.55071Lists
Lists are vectors of arbitrary objects. You can string any kind of objects together in a list. Sometimes the objects are identical, such as when you are doing a massive simulation study and each list element may be a simulated dataset in form of a dataframe. Alternatively, each element of a list may contain a different type of object. This is especially useful for model fitting output, for example, where you may want to store the input data in one list element, and in other list elements: the expression for the model, the fitted parameters, and the information criteria. All of these items are logically related, and if you name the list elements you can easily access the information wanted.
Note that lists have no dimension (because they are more flexible vectors - kinda like stretchy christmas stockings). However, if you have a matrix or a dataframe within a list those will have vectors. The object within lists have their own attributes.
You can access the z element of mylist in a number of ways, using the $ operator and the name of the element, by the index number and double brackets, or by name and double bracket:
mylist$z tom dick harry
[1,] 1 3 5
[2,] 2 4 6
attr(,"names")
[1] "a" "b" "c" "d" "e" "f"names(mylist$z)[1] "a" "b" "c" "d" "e" "f"names(mylist[[4]])[1] "a" "b" "c" "d" "e" "f"names(mylist[["z"]])[1] "a" "b" "c" "d" "e" "f"To see the structure of the list object, use str()
str(mylist)List of 4
$ species: chr [1:3] "a" "b" "c"
$ x : num [1:3] 1 2 4
$ y : num [1:3] 1.551 1.655 0.504
$ z : int [1:2, 1:3] 1 2 3 4 5 6
..- attr(*, "names")= chr [1:6] "a" "b" "c" "d" ...
..- attr(*, "dimnames")=List of 2
.. ..$ : NULL
.. ..$ : chr [1:3] "tom" "dick" "harry"You can see that there are four elements of mylist, a character vector named species, two numeric vectors named x and y, and a integer matrix called z. Is it starting to make sense?
Footnotes
For example, logistic regression (a regression to predict a binary [yes/no] outcome) is used for classification. The underlying model predicts a quantitative outcome (a value between 0 and 1 usually interpreted as a probability), which is then binned to make categorical predictions.↩︎